Proposed Project Summary
I will implement a load balancing framework in Java for latedays1 to evaluate random balancing, round robin balancing, least loaded balancing, and Indeed's boxcar balancing. I will use the framework to perform a detailed analysis of the balancing algorithms individually and to make comparisons between them.
Background
Modern day industry grade systems look different than those of even 10 years ago. A proliferation of reasonably priced and reasonably powerful servers has altered the landscape significantly. Now, it is unlikely that any survey of a randomly selected group of companies with an online presence would find even one without some distributed system among their internal software. And for each such (well architected) distributed system, there will be some form of load balancing scheme.
Load balancing is, loosely, the activity of mapping an incoming request stream onto a set of available workers. Unfortunately (or fortunately, depending on your viewpoint), it is difficult to come up with a single concrete definition for load, or what constitutes a good load balancer. Commonly used metrics for load at either the worker or system level include mean response time and the length of the queue, among others. With some such metric in mind, the goal of a load balancer is to distribute the load across the worker set as uniformly as possible.
There are a number of different classes of algorithm to achieve this goal. The balancing may be either static (determined ahead of time, and hard coded), or dynamic (determined at runtime, in response to the request stream itself). It may be done centrally (by a single stateful balancer, necessitating global synchronization over the whole system) or in a distributed fashion (where clients connect to workers directly, based on partial knowledge of the system). Each scheme has both strengths, and weaknesses, and it the best solution frequently depends on the details of the target request stream.
I have selected four algorithms to analyze, in both centralized and distributed variants:
Load balancing is, loosely, the activity of mapping an incoming request stream onto a set of available workers. Unfortunately (or fortunately, depending on your viewpoint), it is difficult to come up with a single concrete definition for load, or what constitutes a good load balancer. Commonly used metrics for load at either the worker or system level include mean response time and the length of the queue, among others. With some such metric in mind, the goal of a load balancer is to distribute the load across the worker set as uniformly as possible.
There are a number of different classes of algorithm to achieve this goal. The balancing may be either static (determined ahead of time, and hard coded), or dynamic (determined at runtime, in response to the request stream itself). It may be done centrally (by a single stateful balancer, necessitating global synchronization over the whole system) or in a distributed fashion (where clients connect to workers directly, based on partial knowledge of the system). Each scheme has both strengths, and weaknesses, and it the best solution frequently depends on the details of the target request stream.
I have selected four algorithms to analyze, in both centralized and distributed variants:
- Random balancing (centralized): requests are assigned to random workers, by a central server
- Random balancing (distributed): requests are assigned to random workers, by clients themselves
- Round robin balancing (centralized): requests are assigned to workers in order, by a central server
- Round robin balancing (distributed): requests are assigned to workers in order, by clients themselves (overlap certain)
- Least loaded balancing (centralized): requests are assigned to the lightest loaded worker, by a central server
- Least loaded balancing (distributed): requests are assigned to the lightest loaded worker, by clients themselves (possible mis-assignment)
- Highest priority balancing (centralized): request channels are negotiated between clients and workers, by a central server
- Highest priority balancing (distributed): request channels are negotiated between clients and workers, by clients themselves
The Challange
There are two primary axis for this project. First, the design and implementation of a complex load balancing framework, enabling the second, an analysis of the effects of different algorithms on load.
The framework itself will be non-trivial. It must be flexible enough to support the easy addition of new balancing algorithms to make analysis straightforward. This will require extensive architecting. Moreover, I plan to build a framework that enables both actual testing and simulation, with a means for comparison between simulations and tests. This should provide confidence in the simulations, and allow for easier analysis.
The analysis is also non-trivial. It is not immediately clear how to analyze the difference between load balancing algorithms, in a manner that accounts for their intrinsic differences. In particular, it will be important to make sure to tell the whole story - a particular slice of the data may be misleading, and capturing the entire picture will be challenging. Determining the right questions to ask, and answering them satisfactorily will be hard.
The framework itself will be non-trivial. It must be flexible enough to support the easy addition of new balancing algorithms to make analysis straightforward. This will require extensive architecting. Moreover, I plan to build a framework that enables both actual testing and simulation, with a means for comparison between simulations and tests. This should provide confidence in the simulations, and allow for easier analysis.
The analysis is also non-trivial. It is not immediately clear how to analyze the difference between load balancing algorithms, in a manner that accounts for their intrinsic differences. In particular, it will be important to make sure to tell the whole story - a particular slice of the data may be misleading, and capturing the entire picture will be challenging. Determining the right questions to ask, and answering them satisfactorily will be hard.
Resources
The framework will be developed in Java 8 built with Maven, and run on the latedays cluster. No additional computation resources will be required, except for occasional exclusive access to the cluster for simulations (but see platform choice below).
Platform Choice
I need a cluster with a reasonable machine count. Latedays has enough to support small scale simulations, which should be enough for demo purposes. If I determine I need more compute, and it's affordable, I will consider switching to use Amazon's EC2 platform, for much larger scale simulations.
Goals
This is an extremely ambitious project. It is multi-faceted, promises to have very interesting results, and may even be of some significant relevance to those designing load balancers in industry. I make a distinction between the essentials of the project (which I will achieve), and the bonus work (which I will plan to achieve, but may run out of time for).
Essentials
I will use the framework, traces, and implementations to compare these four algorithms. Using these results, I will answer the following questions:
Bonus
Time permitting, I would like to add the following:
Essentials
- I will build a trace generation framework, that supports at least one meaningful distribution. That is, the framework will enable the generation of traces with jobs arriving according to some distribution, and whose completion times follow another distribution (e.g. arrival rates follow a Poisson process, and completion times follow a Weibull distribution).
- I will build a simulation framework, that enables the playback of these traces against an abstracted centralized load balancer algorithm.
- I will implement a centralized version of random, round robin, least loaded, and priority balancing.
I will use the framework, traces, and implementations to compare these four algorithms. Using these results, I will answer the following questions:
- Using mean response time as the load metric, which algorithm is best (for each distribution type considered)?
- Using queue length as the load metric, which algorithm is best (for each distribution type considered)?
- What are the fundamental trade-offs revealed, for choosing between algorithms?
Bonus
Time permitting, I would like to add the following:
- I will extend the simulation framework to a full implementation which runs on a cluster.
- I will run my traces against the cluster, and compare the results against the simulated results for the traces.
- I will answer the preceding questions based on actual data (rather than simulated).
- I will add the decentralized version of each algorithm, and extend my analysis to address the following: when should we prefer centralized to distributed? What are the trade-offs associated with moving between centralized and distributed?
Schedule
A tentative (aggressive) schedule is outlined below, aiming to hit every essential and bonus task.
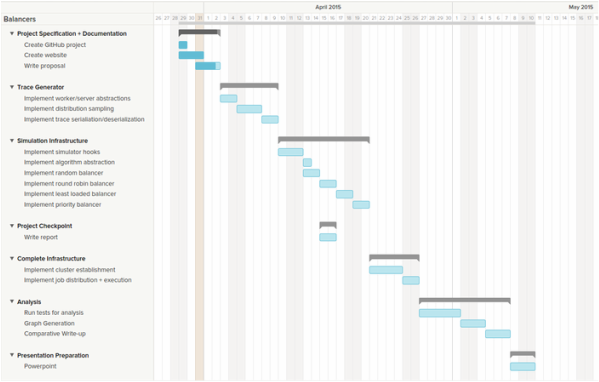
A slightly more textular representation:
| Description | Start | End |
|---|---|---|
| Project Specification + Documentation | 3/25 | 4/2 |
| Trace Generator | 4/2 | 4/10 |
| Simulation Infrastructure | 4/10 | 4/21 |
| Project Checkpoint | 4/14 | 4/16 |
| Complete Infrastructure | 4/21 | 4/26 |
| Analysis | 4/27 | 5/7 |
| Final Report + Presentation Preperation | 5/7 | 5/11 |
1 Latedays is a special purpose computing cluster at Carnegie Mellon University. The cluster is equipped with 15 machines (1 head node + 14 worker nodes). Each machine has the following internals:
- 2 six-core Xeon e5-2620 v3 processors [2.4 GHz, 15MB L3 cache, hyper-threading, AVX2 instruction support]
- 16 GB RAM (60 GB/sec of bandwidth)
- 1 Xeon Phi 5110p co-processor board [60 cores (1 GHz, 4-threads per core, AVX512 ("16-wide") instruction support), 8GB RAM]

