State of the Project
Progress is good. Here's where I am:
Work Breakdown
- Wrote the complete project proposal
- Implemented a variadic trace generator
- Supports distribution based arrival/duration generation
- Generated two testing traces
- Uniform arrival/uniform duration
- Poisson arrival/Weibull duration
- Contacted Indeed to request realistic load data to fit distributions to
- Built RPC/Protobuf based simulation framework
- Implemented random balancing
- Implemented least loaded balancing
- Implemented round robin balancing
- Estimated costs of different systems for deploying a fully functional testing framework.
- Latedays: 15 nodes/free (not ideal - competing with classmates, hard to configure)
- Digital Ocean (exclusive access, easier to configure)
- 5 nodes/$25
- 10 nodes/$50
- 20 nodes/$100
- 30 nodes/$150
- Amazon EC21 (not exclusive access, very easy to configure)
- 10 node test/$2.50
- 64 node test/$5.07
- 128 node test/$8.15
- 256 node test/$14.30
- 512 node test/$26.58
- 1024 node test/$51.15
What Next?
As I look forward, there are two significant areas that I'm focusing on. The first is analysis: I want to slice the data I generate to come up with the most insightful ways of representing the data, and understanding differences in algorithms. At the moment, I'm excited by the prospect of graphing higher order statistical moments (e.g. kurtosis, skewness, etc.) to get a graphical sense for how well load is distributed, and what properties a given system has over time. Traces I'm very interested in generating and running are various degenerate traces - I want to see how the balancers fail, and whether some are more graceful in their degradation.
The second focus area is implementation: I am continuing to build my framework. At the moment, I am transitioning to some practical matters. Namely,
The second focus area is implementation: I am continuing to build my framework. At the moment, I am transitioning to some practical matters. Namely,
- I am getting intermittent RPC failures (silent of course) which throw my data off
- I am porting a log analysis framework from Assignment 4 to handle my new protocols
- I need a way to configure and run the system, using a large node count - nontrivial to configure 512 or 1024 machines
[Updated] Timeline
| Description | Start | End |
|---|---|---|
| Completed Simulator | - | 4/26 |
| Deployment + Executor Configured | 4/24 | 4/27 |
| Generate All Traces | 4/25 | 4/26 |
| Run Trials | 4/27 | 4/30 |
| Analysis | 4/30 | 5/5 |
| Final Report + Presentation | 5/5 | 5/11 |
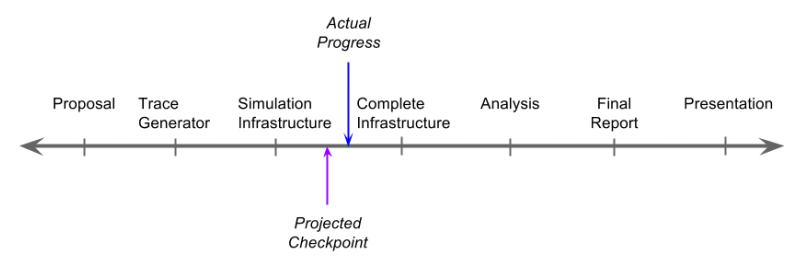
Question: how am I doing on my goals?
Answer: I am on track to deliver all essentials. I am also on track to extend simulator to actual executing balanced pseudo-service. I will likely not have time to implement the decentralized algorithms, and will instead focus on analyzing centralized versions.
Answer: I am on track to deliver all essentials. I am also on track to extend simulator to actual executing balanced pseudo-service. I will likely not have time to implement the decentralized algorithms, and will instead focus on analyzing centralized versions.
[Updated] Deliverables
Essentials [for parallelism competition]:
Bonus (still):
- Completed simulation framework with random, round robin, least loaded, and priority balancing algorithms.
- Answers to the burning questions! In particular evaluation of algorithms (as per proposal)
Bonus (still):
- Full framework (deployed to cluster) with same algorithms
- Traces fitted to Indeed's data (if I get it in time)
Competition Presentation
My presentation will consist largely of graphs. I'll discuss how I built the system (in brief), and then show graphs which break the system down. I'm expecting to look at throughput, queue length, average load, variance of load, skewness of load, and kurtosis of load over time (possibly among other views of the data). The result should be a relatively complete picture of the different algorithms. I hope to shed some light on when to use which!
1 Costs reported assume running all (m1.small, US East) nodes for an hour or less (reasonable for one complete round of tests, running every trace. Traces may be capped arbitrarily: assuming 10 traces, with each trace to run for about 5 minutes, leaving 10 minutes for configuration + slop).

